主要内容 #
综合实战:能简单了解模块化编程的基本流程,掌握python大型程序实现的基本思路。本节课主要简单介绍python中模块的实现和测试10.python模块的中的__name__和__all__变量 #
上节课中我们做好了模块的功能设计,接下来只需要一一实现这些功能即可,首先我们建立一个名为mydic的python包,使你的包中包括我们设计好的module即相应的.py源文件,其中desgin.py是用来设计模块的伪代码,内容的话可以按照上节课示例三写,也可自己设计。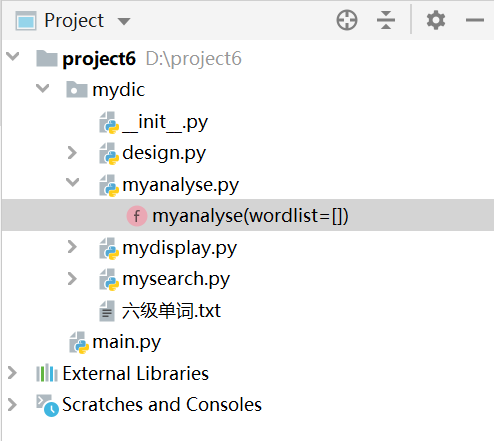 在进行模块编写之前我们首先了解模块中两个比较常用的变量__name__和__all__:
在进行模块编写之前我们首先了解模块中两个比较常用的变量__name__和__all__:
#test1.py
print('test1',__name__)
#test2.py
import test1 as t1
print('test2',__name__)
11.python模块的实现和测试: #
事实上在93课当中,我们已经实现了模块mysearch的功能,我们把它进行简单的封装如下例所示,在检索单词之前,我们定义了myreadcheck()函数,作为myresearch()函数的补充
# coding=gbk
'''模块mysearch'''
import re
def myreadcheck(path='六级单词.txt'):
''' 根据指定的路径,检查该文件是否存在,返回处理文件的路径,以及该文件本身
后续可根据需要对文件进行预处理,调用时需要对check的文件进行关闭'''
try:
file=open(path)
return path,file#返回多个变量时,以tuple的形式返回
except FileNotFoundError:
print('路径{}有错,未找到文件!'.format(path))
return None
def mysearch(head='un',func=myreadcheck,path='六级单词.txt'):
'''高阶函数,根据文件名和开头检索单词,返回由该单词组成的列表
head单词开头部分,path文件路径包括后缀,func文件检测函数目前只检测路径'''
if func(path)==None:#文件不存在直接返回
return
else:
file=func(path)[1]#元组的访问,只需取文件即可
pattern=re.compile(r'\b{}.*\b'.format(head))#正则表达式\b用于单词开头与结尾,找出以un开头的单词,.*匹配除换行符以外的字符串
pattern2=re.compile(r' +')
wordlist=[]#储存字典的列表
for line in file:#逐行读取文件
res2=pattern2.sub(' ',line)
res1=pattern.search(res2)#考虑到每行只有一个单词,使用模式对象的search()逐行检索,返回匹配对象
if res1!=None:#如果匹配对象不为空
wordlist.append(res1.group())#在列表中添加此单词
file.close()
return wordlist
__all__=['mysearch']#保留模块中的myreadcheck函数,使它在from myresearch import *中不被导入
if __name__ == '__main__':#模块测试
print(mysearch(head='mis'))
习题 #
尝试在mysearch()函数中用不同的head参数,对模块mysearch进行测试 思考一下如果在模块测试的代码前,不加入if __name__ == ‘__main__’的条件判断,该模块能运行吗?有什么不好的地方?OJ训练题 #
1、水下探测器 – ★★
2、阿尔法乘积 – ★★
3、近似值 – ★★
4、分解质因数 – ★★★
5、子串统计 – ★★★★



