主要内容 #
- 解释性语言
- 编译性语言
- debug的概念
计算只能识别二进制,任何程序或软件,最终都要经过编译或解释转换成二进制才能被计算机识别。源代码,源代码就是由程序员使用各种编程语言编写的还未经编译或者解释的程序文本,编译或解释能把源代码翻译成等效的二进制代码,也就是CPU能够识别的机器语言。
1. 解释性语言 #
解释型语言(Interpreted language)是一种编程语言类型。这种类型的程式语言,会将程式码一句一句直接执行,不需要像编译语言(Compiled language)一样,经过编译器先行编译为机器码,之后再执行。这种程式语言需要利用直译器,在执行期,动态将程式码逐句直译(interpret)为机器码,或是已经预先编译为机器码的子程式,之后再执行。
许多程式语言同时采用编译器与直译器来实作,其中包括Lisp,Pascal,BASIC 与 Python。JAVA及C#采用混合方式,先将程式码编译为字节码,在执行时再进行直译。
2. 编译性性语言 #
编译型语言:程序在执行之前需要一个专门的编译过程,把程序编译成 为机器语言的文件,运行时不需要重新翻译,直接使用编译的结果就行了。程序执行效率高,依赖编译器,跨平台性差些。如C、C++、Delphi等.
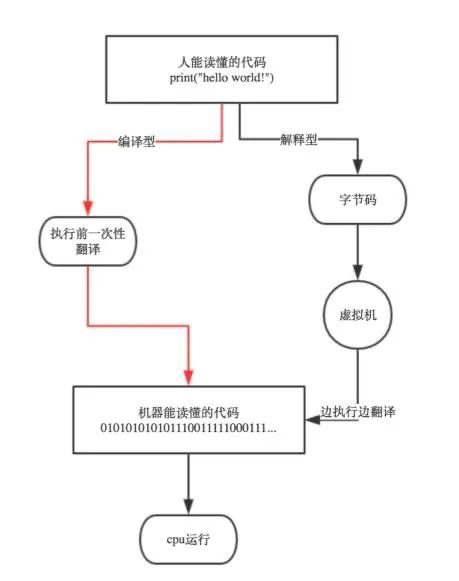
两种语言的对比:
翻译的方式有两种,一个是编译,一个是解释。两种方式只是翻译的时间不同。编译型语言写的程序执行之前,需要一个专门的编译过程,把程序编译成为机器语言的文件,比如exe文件,以后要运行的话就不用重新翻译了,直接使用编译的结果就行了(exe文件),因为翻译只做了一次,运行时不需要翻译,所以编译型语言的程序执行效率高,但也不能一概而论,部分解释型语言的解释器通过在运行时动态优化代码,甚至能够使解释型语言的性能超过编译型语言。
解释则不同,解释性语言的程序不需要编译,省了道工序,解释性语言在运行程序的时候才翻译,比如解释性basic语言,专门有一个解释器能够直接执行basic程序,每个语句都是执行的时候才翻译。这样解释性语言每执行一次就要翻译一次,效率比较低。解释是一句一句的翻译。
3. debug的概念 #
调试(英语:Debug)是发现和减少计算机程序或电子仪器设备中程序错误的一个过程。
编程是一件复杂的工作,因为是人做的事情,所以难免经常出错。据说有这样一个典故:早期的计算机体积都很大,有一次一台计算机不能正常工作,工程师们找了半天原因最后发现是一只臭虫钻进计算机中造成的。从此以后,程序中的错误被叫做臭虫(Bug),而找到这些Bug并加以纠正的过程就叫做调试(Debug)。
调试的技能我们在后续的学习中慢慢培养,但首先我们要区分清楚程序中的Bug分为哪几类。
编译时错误
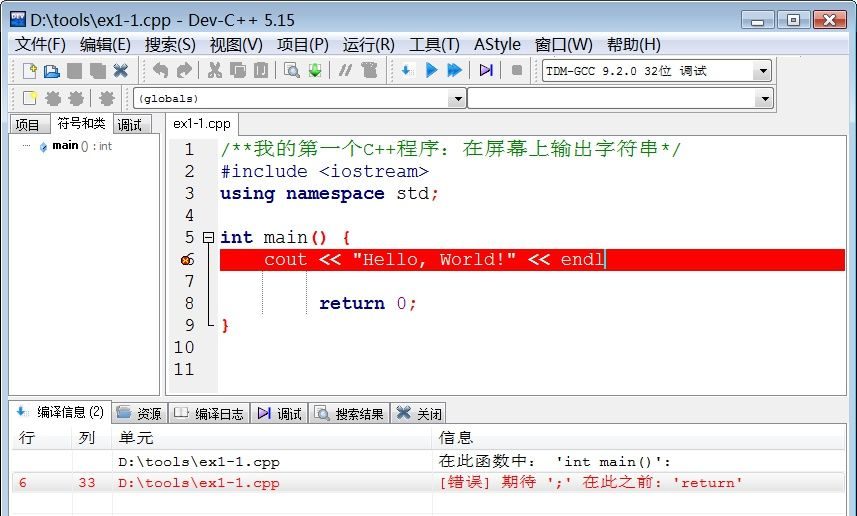
编译器只能翻译语法正确的程序,否则将导致编译失败,无法生成可执行文件。
例如:编译信息第二行指示程序第6行第33列,信息为“[错误] 期待 ‘;’ 在此之前: ‘return’”,这时源程序中已经定位到第6行第33列,该行此时以红色高亮显示。
鼠标双击该行,使之变成正常编辑时的语法高亮方式显示,仔细查看可以发现,实际问题是该行末尾缺少一个分号。修改后再次编译,就能编译成功。
运行时错误
编译器检查不出这类错误,仍然可以生成可执行文件,但在运行时会出错而导致程序崩溃。对于我们接下来的几章将编写的简单程序来说,运行时错误很少见,到了后面的章节你会遇到越来越多的运行时错误。读者在以后的学习中要时刻注意区分编译时和运行时(Run-time)这两个概念,不仅在调试时需要区分这两个概念,在学习C语言的很多语法时都需要区分这两个概念,有些事情在编译时做,有些事情则在运行时做。
例如:由于考虑不周或输入错误导致程序异常(Exception),比如数组越界访问,除数为零,堆栈溢出等等。
逻辑错误和语义错误
第三类错误是逻辑错误和语义错误。如果程序里有逻辑错误,编译和运行都会很顺利,看上去也不产生任何错误信息,但是程序没有干它该干的事情,而是干了别的事情。当然不管怎么样,计算机只会按你写的程序去做,问题在于你写的程序不是你真正想要的,这意味着程序的意思(即语义)是错的。找到逻辑错误在哪需要十分清醒的头脑,要通过观察程序的输出回过头来判断它到底在做什么。



