1. 值传递 #
#include <iostream>
int dashima(int a, int b) // 值传递
{
return a>b ? a:b;
}
int main()
{
int a, b;
cin >> a >> b;
cout << dashima(a,b); // 调用
}
这是一种常见的函数参数形式。
这样形式的函数传参,有一个问题。那就是:
无法返回超过 1 个参数(因为 return 后面只可以有一个元素)。
这种情况下,我们可以使用“引用传递”。
2. 引用传递 #
#include <iostream>
void dashima(int a, int b, int & result) // 引用传递。请尝试一下,没有 & 的结果
{
result = a>b ? a:b;
cout << "result = " << result << endl;
}
int main()
{
int a, b, res;
cin >> a >> b;
cout << dashima(a, b, res); // 调用
}
值传递 和 引用传递的差别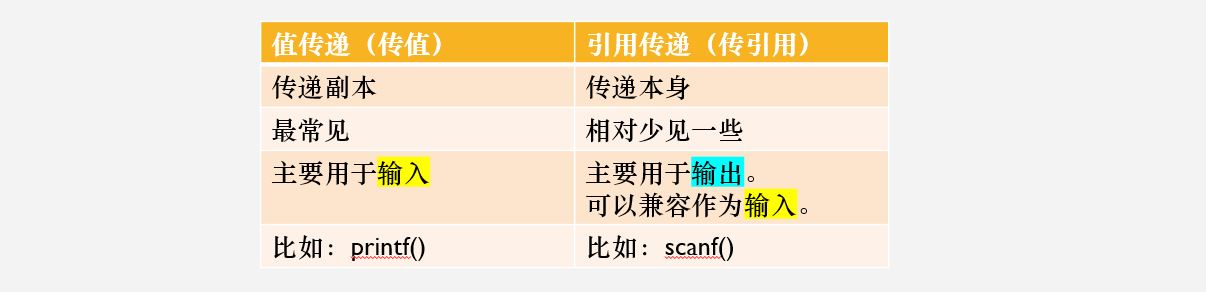
值传递 – 就像孙悟空的分身
引用传递 – 就像孙悟空本尊
3. 指针传递 #
在讲值传递的时候,我们还没有给出数组的传参方式。
#include <iostream>
void dashima(int x[]) // 【请注意,是 int x[]】
{
for(int i=0;i < 4;++i)
cout << x[i] << ",";
}
int main()
{
int x[]={0,1,2,3};
f4(x);
return 0;
}
看似普通的调用方法,其实有一些不同。
请运行下面的例子。
#include <iostream>
void dashima(int a[])
{
for(int i=0;i < 4;++i)
cout << a[i] << ",";
cout << "In dashima, " << sizeof(a) << endl;
}
int main()
{
int x[]={0,1,2,3};
cout << "In main, " << sizeof(x) << endl;
dashima(x);
return 0;
}
输出应该是
In main, 16 0,1,2,3, In dashima, 8 // 这里是因为,函数 dashima 中的数组,其实变成了指针。
请运行下面的例子,验证指针的大小。
#include <iostream>
void dashima(int* a)
{
for(int i=0;i < 4;++i)
cout << x[i] << ",";
cout << "In dashima, " << sizeof(a) << endl;
}
int main()
{
int x[]={0,1,2,3};
cout << "In main, " << sizeof(x) << endl;
dashima(x);
return 0;
}
【C++中,作为函数参数的数组,会转化成指针】
这带来了一个重大的影响
数组的长度,无法在函数中求解。
请解释一下为什么。
所以,为了明确这个变化,在使用一维数组作为形参时,一般明确指明,使用“指针传递”,注意,一般还需要传入数组长度。(请运行)
#include <iostream>
void f4(int* x, int length)
{
for(int i=0; i < length; ++i)
cout << x[i] << ", ";
}
int main()
{
int x[]={0,1,2,3};
f4(x, 4);
return 0;
}
4. 重载 #
4.1 为什么需要重载 #
示例程序:
int compare(int a, int b)
{
return a>b ? a:b;
}
int main()
{
int d(2),a(1),s(21),h(14),i(90),m(-5);
cout << compare(a, b);
cout << compare(1, 2.5); // 【错误】 2.5 是 double 类型,不能传递给 b,这里会发生强制类型转化,导致小数部分丢失。
cout << compare(1, 2, 3); // 【错误】 compare 只接受 3 个参数,编译无法通过
cout << compare(-5, true); // 【错误】 参数类型不对
cout << compare(-5, 'A'); // 【错误】 参数类型不对
...
}
思考:
如果,要接受上述的这种调用方式,那应该怎么办呢?
请看例子
int compare(int a, int b)
{
return a>b ? a:b;
}
double compare(int a, double b)
{
return a>b ? a:b;
}
double compare(double a, int b)
{
return a>b ? a:b;
}
double compare(double a, double b)
{
return a>b ? a:b;
}
int compare(int a, bool b)
{
return a>b ? a:(int)b;
}
int compare(int a, char b)
{
return a>b ? a:(int)b;
}
int main()
{
int d(2),a(1),s(21),h(14),i(90),m(-5);
cout << compare(a, b);
cout << compare(1, 2.5); //
cout << compare(1, 2, 3); // 每一种函数就可以
cout << compare(-5, true); //
cout << compare(-5, 'A'); //
...
}
我们来观察一下以上这些函数的函数签名
int compare(int a, int b) double compare(int a, double b) double compare(double a, int b) double compare(double a, double b) int compare(int a, bool b) int compare(int a, char b)
以上的这些函数,它们的函数名是相同。这种类型的函数定义方法,称为“函数的重载”。
重载的规则:
重载,本质上是定义了一个新的函数
重载,要么形参的类型不同,要么形参的数量不同。
输出类型不同,不能重载
为了更好的理解上述的规则,我们来做几个习题。
4.2 判断题 #
- 请问下面的两个函数是重载吗?
int max_val(int a, int b)
{
return a>b ? a:b;
}
int max_value(int a, int b)
{
return a>b ? a:b;
}
参考答案
/* no,名字不同 */
- 请问下面的两个函数是重载吗?
int max_val(int a, int b)
{
return a>b ? a:b;
}
int max_val(int a, int b, double c)
{
……
}
参考答案
/* yes */
- 请问下面的两个函数是重载吗?
int max_val(int a, int b)
{
return a>b ? a:b;
}
double max_val(int a, int b)
{
……
}
参考答案
/* no,返回类型不同,不能作为重载函数 */
- 请问下面的两个函数是重载吗?
int max_val(int a, int b)
{
return a>b ? a:b;
}
int max_val(int b, int a)
{
……
}
参考答案
/* no,形参的名字不同,不能作为重载函数。只有类型不同才可以。它们的函数签名是相同的,都是:int max_val(int, int) */
- 请问下面的两个函数是重载吗?
int max_val(int a, int b)
{
return a>b ? a:b;
}
int max_val(char ch, int b, int a)
{
……
}
参考答案
/* yes */
- 请问下面的两个函数是重载吗?
int max_val(int a, int b)
{
return a>b ? a:b;
}
int max_val(const int a, int b)
{
……
}
参考答案
/* no, const 仅作为修饰符 */
- 请问下面的两个函数是重载吗?
int max_val(int a, int b)
{
return a>b ? a:b;
}
int max_val(int* a, int b)
{
……
}
参考答案
/* yes */
- 请问下面的两个函数是重载吗?
int max_val(int a, int b)
{
return a>b ? a:b;
}
int max_val(int a[], int b)
{
……
}
参考答案
/* yes */
- 请问下面的两个函数是重载吗?
int dashima(int a, int b, int res)
{
// some code
}
int dashima(int a, int b, int& res)
{
// some code
}
参考答案
/* yes!但是要分情况讨论!! */
请看例子:
int dashima(int a, int b, int res)
{
// some code
}
int dashima(int a, int b, int& res)
{
// some code
}
int main()
{
dashima(4, 5, 6); // 调用 int dashima(int, int, int)
const int da=5;
dashima(6, 5, da); // 调用 int dashima(int, int, int)
int shi;
dashima(7, 5, shi); // 【编译出错】存在两个可以匹配的函数 int dashima(int, int, int) 和 int dashima(int, int, int&)
return 0;
}
重要说明:
函数中,变量的引用传递,包含了输出参数的含义
所以,当需要输出变量时,使用引用类型的形参。此时,请务必避免去重载函数的值传递版本。
也就是说,对于上述的情况,我们推荐这样写:
/*
去除这个版本的函数,不保留 值传递版本 的重载
int dashima(int a, int b, int res)
{
// some code
}
*/
int dashima(int a, int b, int& res)
{
// some code
}
int main()
{
dashima(4, 5, 6); // 调用 int dashima(int, int, int&)
const int da=5;
dashima(6, 5, da); // 调用 int dashima(int, int, int&)
int shi;
dashima(7, 5, shi); // 【编译 OK】调用 int dashima(int, int, int&)
return 0;
}
5. 常量与变量的作用范围 #
5.1 变量和常量 #
int dashima; // 这就是一个变量。 dashima = 5; // 变量可以赋值
变量的值,是可以被改变的。
在 C++ 中,有一些量,它们的值是不变化的。
举例:
// 数值常量 12 -5 3.14159 3.15f true
5.2 变量的作用域 #
每个变量都有作用域,变量的作用域决定了变量定义的生效范围,就如同法律条文一样,一般不同国家的法律条文仅作用于本国,变量仅生效于其作用域。函数内定义的变量的作用域为该函数内,全局变量的作用域为全局。不同函数内定义的变量被视为独立实体,当该函数执行完毕便释放变量所占用的内存空间,即便不同函数内定义的变量名称相同也不会相互影响。
全局变量定义示例:
#include <iostream>
using namespace std;
int a=20;
void Print()
{
cout << a << endl;
}
int main()
{
Print();
cout << a << endl;
}
局部变量定义示例:
#include <iostream>
using namespace std;
int a=20;
void Print()
{
int b=30;
cout<<b<<endl;
cout<<a<<endl;
}
int main()
{
Print();
cout<<a;
//cout<<b;
}
5.3 定义“符号常量” #
除此以外,我们还可以定义“符号常量”
// 符号常量 const int dashima = 5; // 在这里可以理解为初始化。 const int dashi(500); const double b(10); const float c=10; const bool d=true; const char e='A'; // 不可以赋值 dashima = 80; // 编译器会报错。常量不允许被修改。
注意关键字:const
5.4 使用场景 #
常量的重点在于“不变”。所以,一般我们经常将以下的量设置为常量。
示例程序:
#include <iostream>
using namespace std;
const double PI = 3.1415926;
int main()
{
cout << "圆的面积为:" << 5*5*PI;
return 0;
}
5.5 #define #
除了使用 const 来定义常量以外,C++ 语法也支持使用 #define 来定义常量。
但是!
这是比较古老的写法。现代程序开发标准中,大多数情况下,我们都不推荐继续使用 #define
不过,了解这种写法,也是非常必要的。
示例程序:
#include <iostream>
using namespace std;
#define PI 3.1415926; // 使用 #define 定义常量
int main()
{
cout << "圆的面积为:" << 5*5*PI;
return 0;
}
define 一般称为“宏定义”,写在 main 以外。
什么是“宏”呢?
“宏”是计算机科学中创造的概念。表示:一系列人为定义的指令。
它的作用其实就是“相同词替换”,怎么理解呢?
比如上述的示例程序中,程序员写的代码是这样的:
#define PI 3.1415926; cout << "圆的面积为:" << 5*5*PI;
在提交代码给编译器之前,计算机会对代码做一下修改:
#define PI 3.1415926; cout << "圆的面积为:" << 5*5*3.1415926; // 所以有代码中的 PI ,都被替换成了 3.1415926。然后才提交给编译器。



