1. 二分查找的概念 #
二分查找(binary search)又叫做折半查找,它的要求是线性表中的数据必须是关键码有序的,线性表必须采用顺序存储。二分法的的关键思想是:在有序表中取中间值作为比较对象,若给定值与中间值相等则查找成功;若给定值比中间值小则在中间记录的左半区间(假设从小到大有序)查找;若给定值大于中间值;则在中间记录的右半区间查找。不断重复上述过程直到查找成功,或所有查找区域无记录,查找失败为止。
假设有这样一个有序数组{0,1,16,24,35,47,59,62,73,88,99},除0下标外共有10个数字。对它进行查找是否存在62这个数字。可以看看折半算法是如何工作的
2. 二分查找的概念 #
/*二分查找*/
int Binary_Search(int *a, int n, int key){
int low, high, mid;
low = 1; //定义最低下标为记录首位
high = n; //定义最高下标为记录末位
while(low <= high){
mid = (low + high) / 2 //折半
if(key < a[mid]) //若查找值比中间值小
high = mid - 1; //最高下标调整到中位下标小一位
else if(key > a[mid]) //若查找值比中间值大
low = mid + 1;
else
return mid; //若相等则说明mid即为要查找的位置
}
return 0;
}
- 程序运行开始,参数a={0,1,16,24,35,47,59,62,73,88,99},n=10, key=62,第3~5行,此时low=1, high=10, 如下图所示:

- 第6~15行循环,进行查找。
- 第8行,mid计算得到5,由于a[5]=47<key,所以执行了第12行,low=5+1=6a,如下图所示:

- 再次循环,mid=(6+10)/2=8,此时a[8]=73>key,所以执行第10行。high=8-1=7,如下图所示:

- 再次循环,mid=(6+7)/2=6,此时a[8]=59<key,所以执行第12行,low=6+1=7,如下图所示:
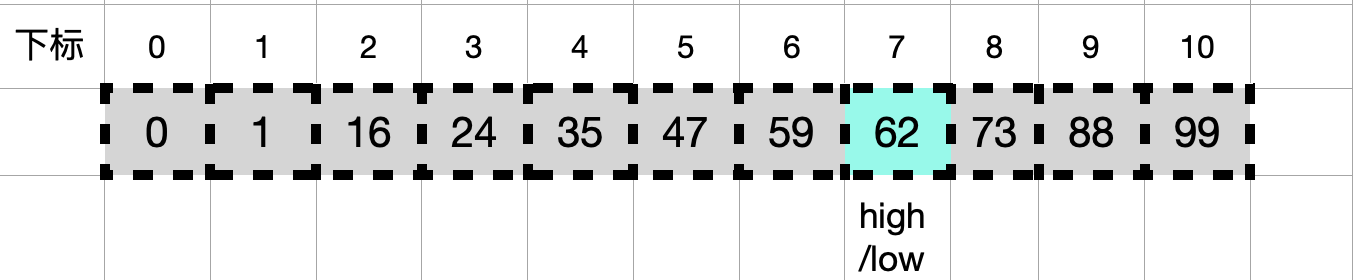
- 再次循环,mid=(7+7)/2=7,此时a[8]=62=key,查找成功,返回7。
3. 二分法的特点 #
该算法还是挺容易理解的,同时也能感觉到它的效率非常高。到底有多高呢?关键在于该算法的时间复杂度。
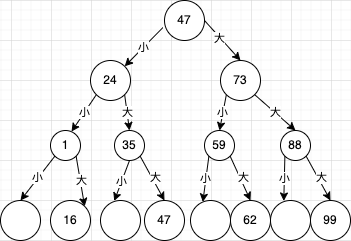
首先将查找过程绘制成一棵二叉树,如下图所示,从图中就可以理解,如果查找的关键字不是中间记录47的话,二分法相当于把有序表分成了两棵子树,查找结果只需要找其中一半的数据即可,等于工作量减少了一半,然后继续二分查找,效率当然非常高了。
根据二叉树的特点,最坏的情况查找到关键字或者查找失败的次数为[log2n]+1。最好的情况当然是一次就找到了。
最终二分法的时间复杂度为O(logn),显然要远优于顺序查找的O(n)时间复杂度了。
不过由于二分查找的前提条件是需要数据有序存储,对于频繁进行插入或者删除操作的数据集来说,维护有序排序会带来不小的工作量,不建议使用。
4. 二分法的实现 #
例题 #
很多人对二分法是又爱又恨,爱是在于它思想简单,效率确实高, 恨是恨在为什么总是写不对呢。二分查找涉及的很多的边界条件,逻辑比较简单,就是写不好。例如 循环中到底是 小于还是小于等于, 到底是+1 呢,还是要-1呢?
接下来我通过一道例题,来让大家一次性彻底掌握二分法。
题目描述:
给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。
示例 1:
输入: nums = [-1,0,3,5,9,12], target = 9 输出: 4 解释: 9 出现在 nums 中并且下标为 4
示例 2:
输入: nums = [-1,0,3,5,9,12], target = 2 输出: -1 解释: 2 不存在 nums 中因此返回 -1
- 你可以假设 nums 中的所有元素是不重复的。
- n 将在 [1, 10000]之间。
- nums 的每个元素都将在 [-9999, 9999]之间。
思路:
这道题目的前提是数组为有序数组,同时题目还强调数组中无重复元素,因为一旦有重复元素,使用二分查找法返回的元素下标可能不是唯一的,这些都是使用二分法的前提条件,当大家看到题目描述满足如上条件的时候,可要想一想是不是可以用二分法了。
二分查找涉及的很多的边界条件,逻辑比较简单,但就是写不好。例如到底是 while(left < right) 还是 while(left <= right),到底是right = middle呢,还是要right = middle – 1呢?
写二分法,区间的定义一般为两种,左闭右闭即[left, right],或者左闭右开即[left, right)。
下面用这两种区间的定义分别讲解两种不同的二分写法。
第一种写法 #
第一种写法,我们定义 target 是在一个在左闭右闭的区间里,也就是[left, right] (这个很重要非常重要)。
区间的定义这就决定了二分法的代码应该如何写,因为定义target在[left, right]区间,所以有如下两点:
while (left <= right) 要使用 <= ,因为left == right是有意义的,所以使用 <=
if (nums[middle] 7> target) right 要赋值为 middle – 1,因为当前这个nums[middle]一定不是target,那么接下来要查找的左区间结束下标位置就是 middle – 1
例如在数组:1,2,3,4,7,9,10中查找元素2,如图所示: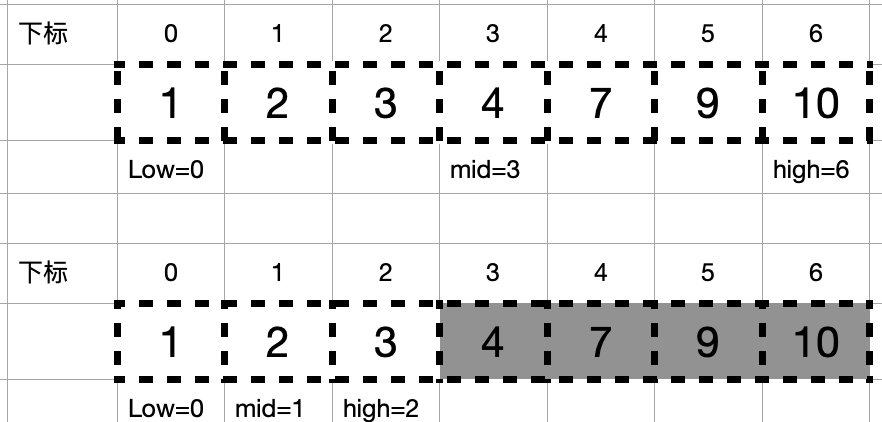
代码如下:(详细注释)
// 版本一
class Solution {
public:
int search(vector<int>& nums, int target) {
int low = 0;
int high = nums.size() - 1; // 定义target在左闭右闭的区间里,[left, right]
while (low <= high) { // 当left==right,区间[left, right]依然有效,所以用 <=
int mid = low + ((high - low) / 2);// 防止溢出 等同于(left + right)/2
if (nums[mid] > target) {
high = mid - 1; // target 在左区间,所以[left, middle - 1]
} else if (nums[mid] < target) {
low = mid + 1; // target 在右区间,所以[middle + 1, right]
} else { // nums[middle] == target
return mid; // 数组中找到目标值,直接返回下标
}
}
// 未找到目标值
return -1;
}
};
第二种写法 #
如果说定义 target 是在一个在左闭右开的区间里,也就是[left, right) ,那么二分法的边界处理方式则截然不同。
有如下两点:
while (left < right),这里使用 < ,因为left == right在区间[left, right)是没有意义的
if (nums[middle] > target) right 更新为 middle,因为当前nums[middle]不等于target,去左区间继续寻找,而寻找区间是左闭右开区间,所以right更新为middle,即:下一个查询区间不会去比较nums[middle]
在数组:1,2,3,4,7,9,10中查找元素2,如图所示:(注意和方法一的区别)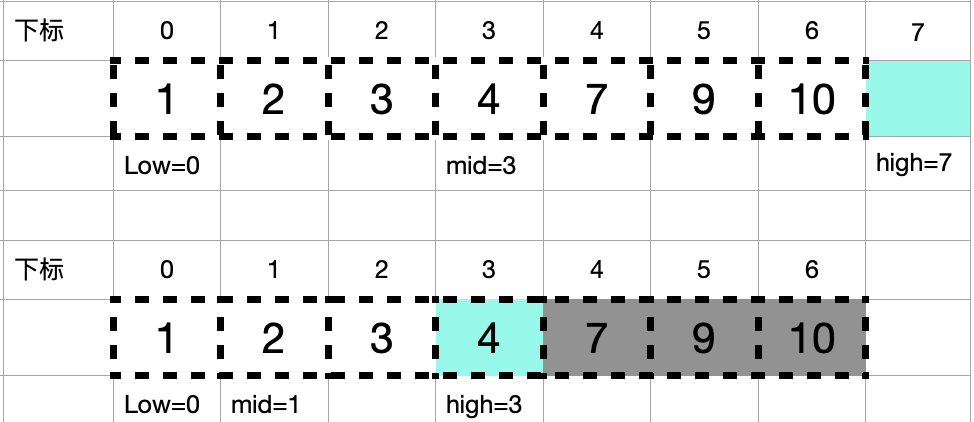
代码如下:(详细注释)
// 版本二
class Solution {
public:
int search(vector<int>& nums, int target) {
int low = 0;
int high = nums.size(); // 定义target在左闭右开的区间里,即:[left, right)
while (low < high) { // 因为left == right的时候,在[left, right)是无效的空间,所以使用 <
int mid = low + ((high - low) >> 1);
if (nums[mid] > target) {
high = mid; // target 在左区间,在[left, middle)中
} else if (nums[mid] < target) {
low = mid + 1; // target 在右区间,在[middle + 1, right)中
} else { // nums[middle] == target
return mid; // 数组中找到目标值,直接返回下标
}
}
// 未找到目标值
return -1;
}
};
5. 例题1 #
第一个和最后一个位置 #
给你一个按照非递减顺序排列的整数数组 nums,和一个目标值 target。请你找出给定目标值在数组中的开始位置和结束位置。
如果数组中不存在目标值 target,返回 [-1, -1]。
你必须设计并实现时间复杂度为 O(log n) 的算法解决此问题。
示例1
输入:nums = [5,7,7,8,8,10], target = 8 输出:[3,4]
示例2
输入:nums = [5,7,7,8,8,10], target = 6 输出:[-1,-1]
示例3
输入:nums = [5,7,7,8,8,10], target = 6 输出:[-1,-1]
求解思路 #
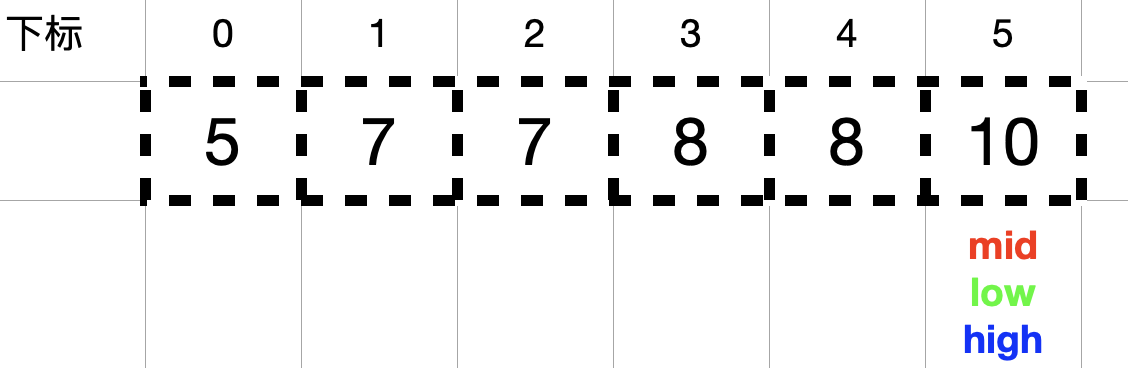
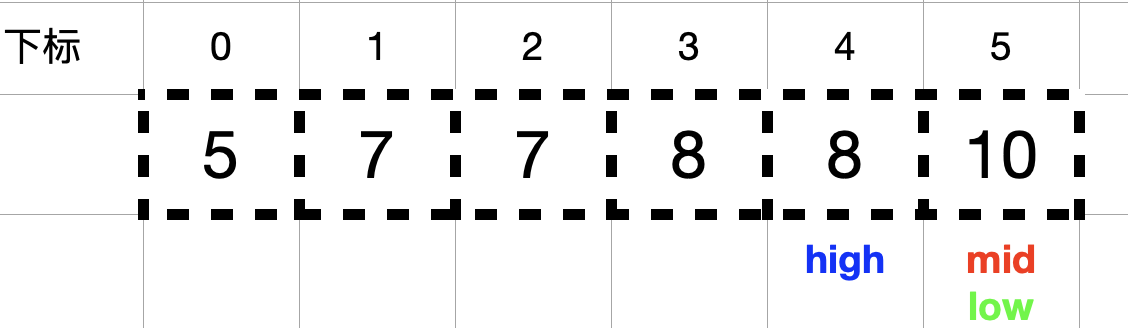
1. 由于题目告知这个数组是升序排列的,所以可以通过二分查找的方法来解答此题;
2. 如何查找元素的第一个位置?利用二分查找找到数组中某元素值等于目标值 target 时,不像二分查找的模板那样立即返回(数组中有多个元素值等于 target),而是通过缩小查找区间的上边界 high (令high= mid – 1),不断向 mid 的左侧收缩,最后达到锁定左边界(元素的第一个位置)的目的;
3. 如何查找元素的最后一个位置?同查找元素的第一个位置类似,在查找到数组中某元素值等于目标值 target 时,不立即返回,通过增大查找区间的下边界 low (令low= mid + 1),不断向 mid 的右侧收缩,最后达到锁定右边界(元素的最后一个位置)的目的;
4. 没有找到,则直接返回 [-1,-1]。
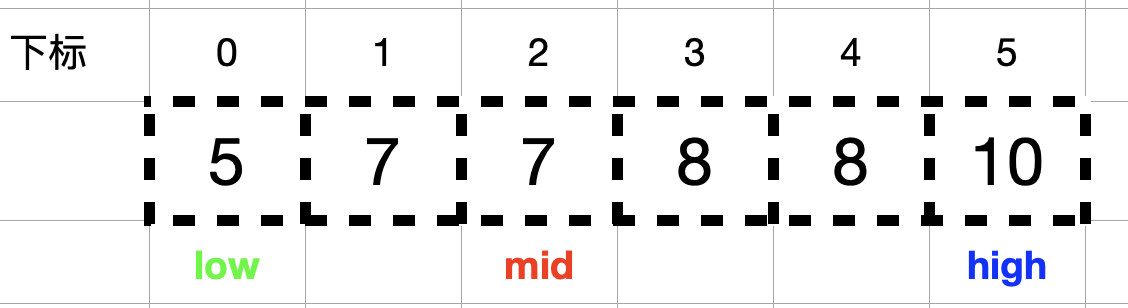
以 nums = [5,7,7,8,8,10], target = 8 为栗子,通过下图来找出目标值 8 在数组中出现的第一个和最后一个位置。如下图示:
查找 8 出现的第一个位置:
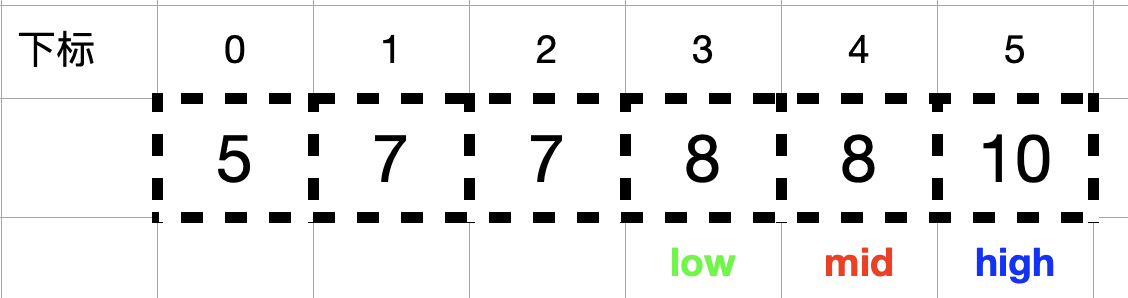
由于此时 nums[mid] = 7 < target = 8,所以需要在右半区间 (mid, high] 中查找,即 low = mid + 1 = 3, mid = (high + low) /2 = 4。
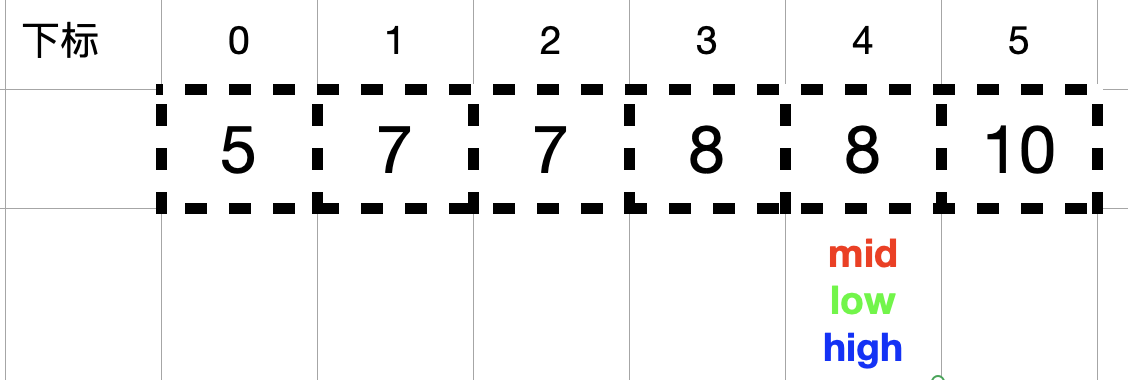
此时nums[mid] = 8 == target = 8, 按照解题思路方法一中 2 的描述,找到数组中元素值等于目标值 target 时,不立即返回,而是缩小查找区间的上边界 high (令 high = mid – 1 = 3),不断向 mid 的左侧收缩, mid = (high + low) / 2 = 3。
继续缩小查找区间的上边界 high。
由于此时 high < low,代表查找 8 在数组中出现的第一个位置结束。
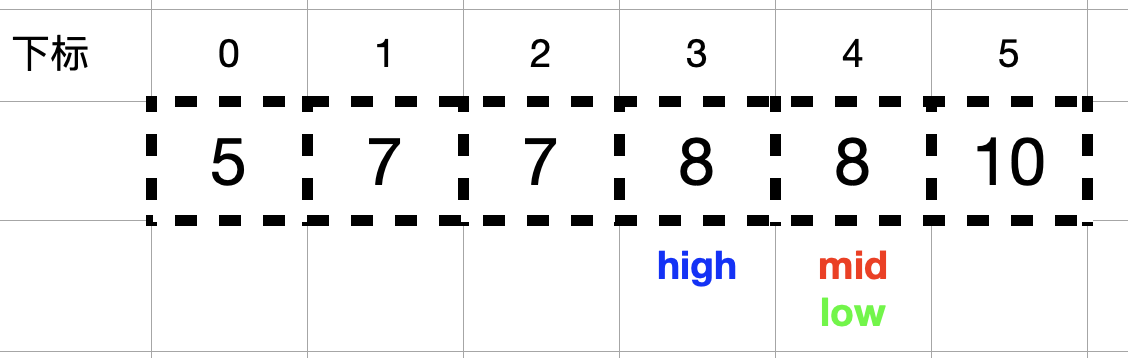
查找 8 出现的最后一个位置:
前两步跟查找 8 出现的第一个位置一样。
此时nums[mid] = 8 == target = 8, 按照解题思路方法一中 3 的描述,找到数组中元素值等于目标值 target 时,不立即返回,而是增大查找区间的下边界 low (令 low = mid + 1 = 5),不断向 mid 的右侧收缩,mid = (high + low) / 2 = 5。
此时,nums[mid] = 10 > target = 8,high = mid – 1 = 4 。
由于此时 high = 4 < low = 5,结束查找,代表查找 8 在数组中出现的最后一个位置结束。
参考代码 #
int GetTargetPosition(int* nums, int numsSize, int target, int locFlag) {
int last = -1;
int low = 0, high = numsSize - 1;
while (low <= high) {
int mid = low + ((high - low) >> 1);
if (nums[mid] < target) {
low = mid + 1;
} else if (nums[mid] > target) {
high = mid - 1;
} else if (nums[mid] == target) {
last = mid;
if (locFlag == 0) {
high = mid - 1;
} else {
low = mid + 1;
}
}
}
return last ;
}
int* searchRange(int* nums, int numsSize, int target, int* returnSize){
int* res = (int *)malloc(2 * sizeof(int));
memset(res, -1, 2 * sizeof(int));
*returnSize = 2;
if (nums == NULL || numsSize < 1) {
return res;
}
/* 通过 locFlag 标志区分查找的元素的位置在一个还是最后一个 */
int firstPos = GetTargetPosition(nums, numsSize, target, 0);
int lastPos = GetTargetPosition(nums, numsSize, target, 1);
/* 数组中没有目标元素 */
if (firstPos == -1 || lastPos == -1) {
return res;
}
res[0] = firstPos;
res[1] = lastPos;
return res;
}
6. 例题2 #
搜索二维矩阵 #
编写一个高效的算法来判断 m x n 矩阵中,是否存在一个目标值。该矩阵具有如下特性:
每行中的整数从左到右按升序排列。
每行的第一个整数大于前一行的最后一个整数。
示例1
输入:matrix = [[1,3,5,7],[10,11,16,20],[23,30,34,60]], target = 3 输出:true
示例2
输入:matrix = [[1,3,5,7],[10,11,16,20],[23,30,34,60]], target = 13 输出:false
求解思路1 #
由于二维矩阵固定列的「从上到下」或者固定行的「从左到右」都是升序的。
因此我们可以使用两次二分来定位到目标位置:
- 第一次二分:从第 0 列中的「所有行」开始找,找到合适的行 row
- 第二次二分:从 row 中「所有列」开始找,找到合适的列 col
- 技巧:在搜索所在行的时候,以最后一列的值与target大小作为收缩边界的判断依据
求解思路2 #
若将矩阵每一行拼接在上一行的末尾,则会得到一个升序数组,我们可以在该数组上二分找到目标元素。
代码实现时,可以二分升序数组的下标,将其映射到原矩阵的行和列上。
参考代码 #
思路1代码
class Solution {
public:
bool searchMatrix(vector<vector<int>>& matrix, int target) {
if(matrix.empty() || matrix[0].empty()) {
return false;
}
int row = matrix.size();
int col = matrix[0].size();
//二分查找行数
int up = 0;
int down = row - 1;
while(up < down) {
int mid = up + (down - up) / 2;
if(matrix[mid][col-1] < target) { //这一行的最后一个值比target还要小,收缩上边界
//下一轮搜索范围[mid + 1, down]
up = mid + 1;
} else {
down = mid;
}
}
//二分查找所在列
int left = 0;
int right = col - 1;
while(left < right) {
int mid = left + (right - left) / 2;
if(matrix[up][mid] < target) { //mid<target,收缩左边界
//下一轮搜索范围[mid+1,right]
left = mid + 1;
} else {
right = mid;
}
}
if(matrix[up][left] == target) {
return true;
}
return false;
}
};
思路2代码
class Solution {
public:
bool searchMatrix(vector<vector<int>>& matrix, int target) {
int m = matrix.size(), n = matrix[0].size();
int low = 0, high = m * n - 1;
while (low <= high) {
int mid = (high - low) / 2 + low;
int x = matrix[mid / n][mid % n];
if (x < target) {
low = mid + 1;
} else if (x > target) {
high = mid - 1;
} else {
return true;
}
}
return false;
}
};



