1. 排序概述 #
何为排序 #
排序是我们生活中经常遇到的问题,同学们出操的时候会按照从矮到高排列;老师查看上课出勤情况时,会按照学生的学号顺序点名;高考录取时会按照学生总分降序录取。这些都涉及到排序的概念。
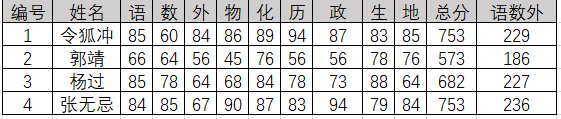
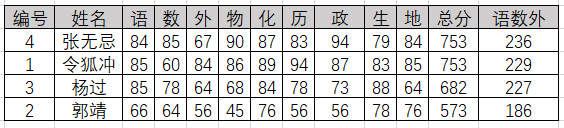
排序的依据可以有不同种类,这种依据被称为关键字。如图所示,某学校为了选拔在主科上更为优秀的学生,要求对所有学生科目总分降序排列,并且在总分相同的情况下对语数外总分做降序排名,这里的总成绩就是主关键字,而语数外的总成绩是次关键字。
排序前:
排序后:
排序的稳定性 #
也正是由于排序不仅是针对主关键字,那么对于此关键字,因为待排序的
记录序列中可能存在两个或者两个以上的关键字相等的记录,排序结果可能存在不唯一的情况,我们给出了稳定与不稳定的定义:
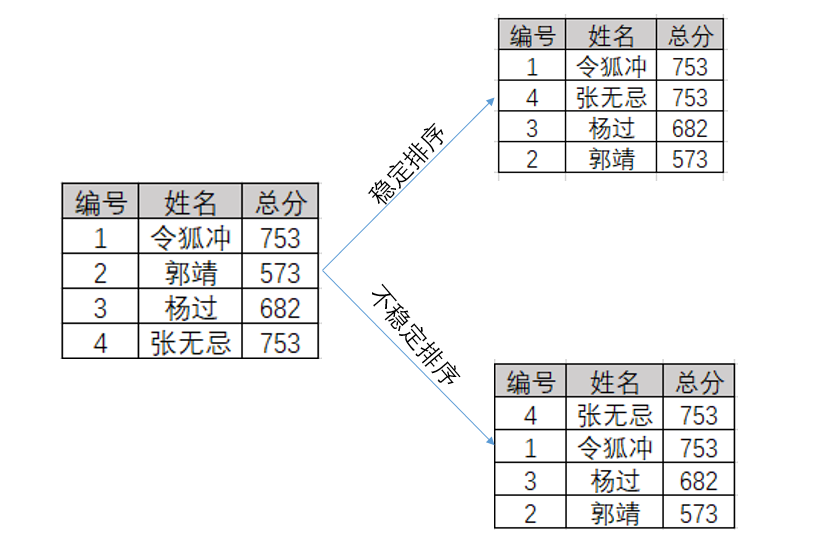
假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。
如下图所示:经过对总分排序后,总分高的排在前列。此时对于令狐冲和张无忌而言,未排序时时张无忌在前,那么它们总分排序后,分数相等的令狐冲依然在前,这样才算是稳定排序,如果他们二者颠倒了,此排序就是不稳定的了。
排序的时间复杂度 #
排序是数据处理中经常执行的一种操作,往往属于系统的核心部分,因此排序算法的时间开销是衡量其好坏的重要标志。在内排序中,主要进行两种操作:比较和移动。比较是指关键字之间的比较,这是要做排序最起码的操作。移动是指记录从一个位置移动到另一个位置,高效的排序算法应该尽量减少关键字比较和记录的移动次数。
O ( 1 ) , O ( n ) , O ( l o g n ) , O ( n l o g n ) O(1), O(n), O(logn), O(nlogn)O(1),O(n),O(logn),O(nlogn)可以看作既可表示算法复杂度,也可以表示时间复杂度。
O后面的括号中有一个函数,指明某个算法的耗时/耗空间与数据增长量之间的关系。其中的n代表输入数据的量。
比如时间复杂度为O(n),就代表数据量增大几倍,耗时也增大几倍。比如常见的遍历算法。
再比如时间复杂度O(n^2),就代表数据量增大n倍时,耗时增大n的平方倍,这是比线性更高的时间复杂度。比如冒泡排序,就是典型的O(n^2)的算法,对n个数排序,需要扫描n×n次。
再比如O(logn),当数据增大n倍时,耗时增大logn倍(这里的log是以2为底的,比如,当数据增大256倍时,耗时只增大8倍,是比线性还要低的时间复杂度)。二分查找就是O(logn)的算法,每找一次排除一半的可能,256个数据中查找只要找8次就可以找到目标。
O(nlogn)同理,就是n乘以logn,当数据增大256倍时,耗时增大256*8=2048倍。这个复杂度高于线性低于平方。归并排序就是O(nlogn)的时间复杂度。
O(1)就是最低的时空复杂度了,也就是耗时/耗空间与输入数据大小无关,无论输入数据增大多少倍,耗时/耗空间都不变。 哈希算法就是典型的O(1)时间复杂度,无论数据规模多大,都可以在一次计算后找到目标(不考虑冲突的话)
排序的空间复杂度 #
空间复杂度(Space Complexity)是对一个算法在运行过程中临时占用存储空间大小的量度,记做S(n)=O(f(n))。比如直接插入排序的时间复杂度是O(n^2),空间复杂度是O(1) 。而一般的递归算法就要有O(n)的空间复杂度了,因为每次递归都要存储返回信息。一个算法的优劣主要从算法的执行时间和所需要占用的存储空间两个方面衡量。
冒泡排序,简单选择排序,堆排序,直接插入排序,希尔排序的空间复杂度为O(1),因为需要一个临时变量来交换元素位置,(另外遍历序列时自然少不了用一个变量来做索引)
快速排序空间复杂度为logn(因为递归调用了) ,归并排序空间复杂是O(n),需要一个大小为n的临时数组。
2. 选择排序 #
选择排序的步骤 #
#
1. 首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置。2. 再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。3. 重复第二步,直到所有元素均排序完毕。
例程 #
题目描述
输入n整数,排序后并输出。
输入
第一行一个整数n,表示要排序的数个数。
第二行n个元素,表示待排序的元素。
数据范围:1≤n≤1000,序列中的元素范围在[-10^6,10^6]之间。
输出
输出n个数字,表示排序后的数字。
样例输入
5
-1 2 1 4 3
样例输出
-1 1 2 3 4
参考程序
#include < iostream >
using namespace std;
void selectSort(int *nums,int n)
{
for(int i=0;i<n-1;i++)
{
int min=i;
for(int j=i+1;j<n;j++)
{
if(nums[j]<nums[min])
min=j; //找出最小值
}
swap(nums[min],nums[i]);
}
}
int main()
{
int nums[1001];
int n;
cin>>n;
for(int i=0;i<n;i++)
{
cin>>nums[i];
}
selectSort(nums, n);
for(int i=0;i<n;i++)
{
if(i != n - 1){
cout << nums[i] << " ";
} else {
cout <<nums[i] << endl;
}
}
return 0;
}
3. 插入排序 #
插入排序步骤 #
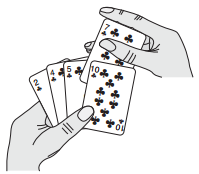
插入排序的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在实现上,通常采用in-place排序(即只需用到O(1)的额外空间的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
插入排序操作类似于摸牌并将其从大到小排列。每次摸到一张牌后,根据其点数插入到确切位置。
如上图:表示的是摸到草花7后进行插入的过程。忽略最右边的草花10,相当于一开始7在最右边,然后逐个与左边的牌相比较(当然左边的牌早已排好顺序),将其放置在合适的位置。当摸到草花10后重复上述过程即可。
插入排序算法的实现步骤可以概括为:
① 从第一个元素开始,该元素可以认为已经被排序 ② 取出下一个元素,在已经排序的元素序列中从后向前扫描 ③如果该元素(已排序)大于新元素,将该元素移到下一位置 ④ 重复步骤③,直到找到已排序的元素小于或者等于新元素的位置 ⑤将新元素插入到该位置后 ⑥ 重复步骤②~⑤
例程 #
题目描述
给定包含N个元素的数组a1,a2,a3,…,aN,利用插入排序将其排成升序,
每次拿出未排序部分中的第一个元素,插入到已排序部分中,排在首个不大于这个元素的后面。
输入
2行
第1行包含1个正整数N(1 < N <= 10000),代表数组元素个数
第2行包含N个整数,空格隔开。
输出
N-1行,既依次输出每趟选择排序后的数组。
样例输入
4
4 3 1 2
样例输出
3 4 1 2
1 3 4 2
1 2 3 4
参考程序
#include < iostream >
using namespace std;
void insertion_sort(int arr[], int len)
{
for (int i = 1; i < len; i++)
{ //当前需要插入的数据
int key = arr[i];
//需要插入的位置
int j = i - 1;
while ((j >= 0) && (key < arr[j]))
{
arr[j + 1] = arr[j];
j--;
}
//插入数据
arr[j + 1] = key;
for(int k = 0; k < len; ++k){
cout << arr[k] << ' ';
}
cout << endl;
}
}
int main()
{
int arr[10001];
int N;
cin >> N;
for(int i = 0; i < N; ++i){
cin >> arr[i];
}
insertion_sort(arr, N);
return 0;
}
4. 冒泡排序 #
冒泡排序步骤 #
作为最简单的排序算法之一,它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。计算步骤如下:
1. 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
2. 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
3. 针对所有的元素重复以上的步骤,除了最后一个。
4. 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。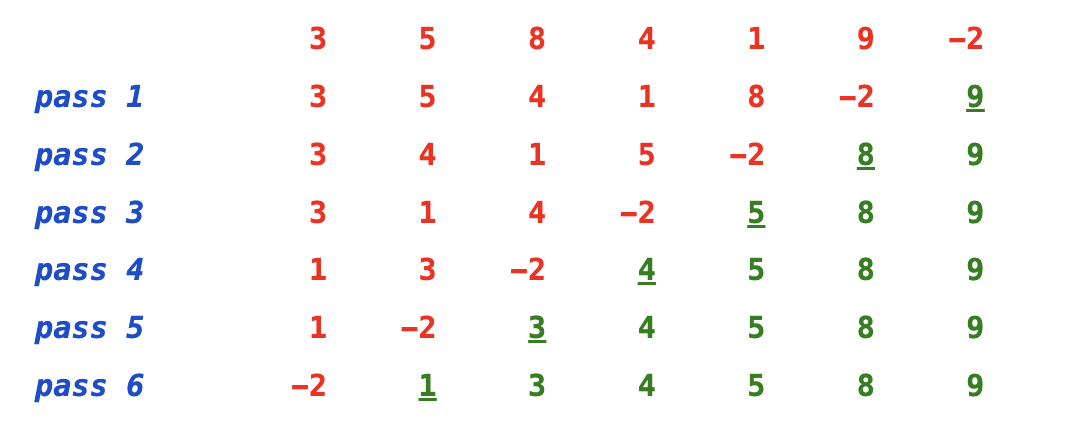
冒泡排序练习 #
题目描述
在一次考试中,每个学生的成绩都不相同,现在知道了每个学生的学号和成绩,求考第k名学生的学号和成绩。
输入
第一行有两个整数,分别是学生的人数n(1~100),和k(1~n)。
其后有n行数据,每行数据包括一个学号(整数)和一个成绩(浮点数),中间用一个空格分隔。
输出
第k名学生的学号和成绩,中间用空格分开。
样例输入
5 3
90788001 67.8
90788002 90.3
90788003 61
90788004 68.4
90788005 73.9
样例输出
90788004 68.4
参考程序
#include < iostream >
#include < string >
using namespace std;
string num[1001];
double s[1001];
int main(){
int i, n, a, b, c, k, j;
string r;
double t;
//输入数据的行数和要求的学生的名次
cin >> n >> k;
//输入学生学号和成绩
for(i = 1; i <= n; ++i){
cin >> num[i] >> s[i];
}
//进行冒泡排序
for(i = 1; i <= n - 1; ++ i){
for(j = i + 1; j <= n; ++j){
if(s[i] < s[j]){
//当条件成立,交换学号和成绩
swap(s[i], s[j]);
swap(num[i], num[j]);
}
}
}
//输出学号和成绩
cout << num[k] << ' ' << s[k] << endl;
return 0;
}
字符串的冒泡排序 #
题目描述
我们已经知道了将N个整数按从小到大排序的冒泡排序法。本题要求将此方法用于字符串序列,并对任意给定的K(K<n),输出扫描完第k遍后的中间结果序列。
输入
输入在第1行中给出N和K(1≤K<n≤100),此后n行,每行包含一个长度不超过10的、仅由小写英文字母组成的非空字符串。
样例输入
6 2
best
cat
east
a
free
day
样例输出
best
a
cat
day
east
free
参考程序
#include < iostream >
#include < string >
using namespace std;
int main(){
int n,k;
cin >> n >> k;
string s[101];
for(int i=0;i<n;i++){
cin>>s[i];
}
for(int i=0;i<k;i++){
for(int a=0;a<n-1;a++){
if(s[a]>s[a+1]){
string t=s[a];
s[a]=s[a+1];
s[a+1]=t;
}
}
}
for(int i=0;i>n-1;i++){
cout<<s[i]<<endl;
}
cout<<s[n-1];
return 0;
}
5. 计数排序(桶排序) #
算法讲解 #
桶排序(Bucket sort)或所谓的箱排序,是一个排序算法,工作的原理是将数组分到有限数量的桶里。每个桶再个别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排序)。
计算步骤 #
一般来说,具体算法描述如下:
- 设置一个定量的数组当作空桶子。
- 寻访序列,并且把项目一个一个放到对应的桶子去。
- 对每个不是空的桶子进行排序。
- 从不是空的桶子里把项目再放回原来的序列中。
过程模拟 #
原始数据: 1 1 5 2 6 9 3 4 1 5 4 4 9 3 6 4 7 6 8 排序结果: 0号桶 0(个数据) 1号桶 3(个数据) 2号桶 1(个数据) 3号桶 2(个数据) 4号桶 4(个数据) 5号桶 2(个数据) 6号桶 2(个数据) 7号桶 1(个数据) 8号桶 1(个数据) 9号桶 1(个数据) 按照有序桶的顺序输出结果。
元素分配到桶中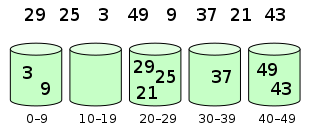
对桶中元素排序
例程 #
#include < iostream >
using namespace std;
const int NUM_BIN = 10; // number of bins.
int main()
{
int a[] = { 1, 1, 5, 2, 6, 9, 3, 4, 1, 5, 4, 4, 9, 3, 6, 4, 7, 6, 8 };
int b[NUM_BIN] = { 0 };
int n = sizeof(a) / sizeof(int);
for (int i = 0; i < n; ++i)
b[a[i]]++;
for (int i = 0; i <= NUM_BIN; ++i)
{
while (b[i] > 0)
{
cout << i << " ";
b[i]--;
}
}
return 0;
}
复杂度分析 #
桶排序是计数排序的升级版。它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。为了使桶排序更加高效,我们需要做到这两点:
1. 在额外空间充足的情况下,尽量增大桶的数量
2. 使用的映射函数能够将输入的 N 个数据均匀的分配到 K 个桶中
同时,对于桶中元素的排序,选择何种比较排序算法对于性能的影响至关重要。
当要被排序的数组内的数值是均匀分配的时候,桶排序使用线性时间(O(n))。



