1. 链表是什么 #

链表又称单链表、链式存储结构,用于存储逻辑关系为“一对一”的数据。
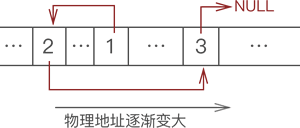
和顺序表不同,使用链表存储数据,不强制要求数据在内存中集中存储,各个元素可以分散存储在内存中。例如,使用链表存储 {1,2,3},各个元素在内存中的存储状态可能是:
可以看到,数据不仅没有集中存放,在内存中的存储次序也是混乱的。那么,链表是如何存储数据间逻辑关系的呢?
链表存储数据间逻辑关系的实现方案是:为每一个元素配置一个指针,每个元素的指针都指向自己的直接后继元素,如下图所示:
显然,我们只需要记住元素 1 的存储位置,通过它的指针就可以找到元素 2,通过元素 2 的指针就可以找到元素 3,以此类推,各个元素的先后次序一目了然。
像图 2 这样,数据元素随机存储在内存中,通过指针维系数据之间“一对一”的逻辑关系,这样的存储结构就是链表。
2. 结点(节点) #


很多教材中,也将“结点”写成“节点”,它们是一个意思。
在链表中,每个数据元素都配有一个指针,这意味着,链表上的每个“元素”都长下图这个样子:
数据域用来存储元素的值,指针域用来存放指针。数据结构中,通常将上图这样的整体称为结点。
也就是说,链表中实际存放的是一个一个的结点,数据元素存放在各个结点的数据域中。举个简单的例子,图 2 中 {1,2,3} 的存储状态用链表表示,如下图所示:
在 C 语言中,可以用结构体表示链表中的结点,例如:
typedef struct link{
char elem; //代表数据域
struct link * next; //代表指针域,指向直接后继元素
}Link;
我们习惯将结点中的指针命名为 next,因此指针域又常称为“Next 域”。
3. 头结点、头指针和首元结点 #
图 4 所示的链表并不完整,一个完整的链表应该由以下几部分构成:
1. 头指针:一个和结点类型相同的指针,它的特点是:永远指向链表中的第一个结点。上文提到过,我们需要记录链表中第一个元素的存储位置,就是用头指针实现。
2. 结点:链表中的节点又细分为头结点、首元结点和其它结点:
- 头结点:某些场景中,为了方便解决问题,会故意在链表的开头放置一个空结点,这样的结点就称为头结点。也就是说,头结点是位于链表开头、数据域为空(不利用)的结点。
- 首元结点:指的是链表开头第一个存有数据的结点。
- 其他节点:链表中其他的节点。
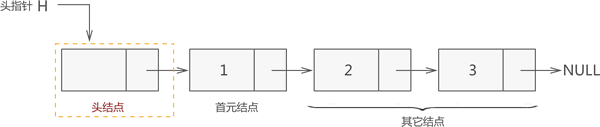
也就是说,一个完整的链表是由头指针和诸多个结点构成的。每个链表都必须有头指针,但头结点不是必须的。
例如,创建一个包含头结点的链表存储 {1,2,3},如下图所示:
再次强调,头指针永远指向链表中的第一个结点。换句话说,如果链表中包含头结点,那么头指针指向的是头结点,反之头指针指向首元结点。
4. 单链表 #
单链表的创建 #
创建一个链表,实现步骤如下:
- 定义一个头指针;
- 创建一个头结点或者首元结点,让头指针指向它;
- 每创建一个结点,都令其直接前驱结点的指针指向它。
例如,创建一个存储 {1,2,3,4} 且无头节点的链表,C 语言实现代码为:
Link* initLink() {
int i;
//1、创建头指针
Link* p = NULL;
//2、创建首元结点
Link* temp = (Link*)malloc(sizeof(Link));
temp->elem = 1;
temp->next = NULL;
//头指针指向首元结点
p = temp;
//3、每创建一个结点,都令其直接前驱结点的指针指向它
for (i = 2; i < 5; i++) {
//创建一个结点
Link* a = (Link*)malloc(sizeof(Link));
a->elem = i;
a->next = NULL;
//每次 temp 指向的结点就是 a 的直接前驱结点
temp->next = a;
//temp指向下一个结点(也就是a),为下次添加结点做准备
temp = temp->next;
}
return p;
}
再比如,创建一个存储 {1,2,3,4} 且含头节点的链表,则 C 语言实现代码为:
Link* initLink() {
int i;
//1、创建头指针
Link* p = NULL;
//2、创建头结点
Link* temp = (Link*)malloc(sizeof(Link));
temp->elem = 0;
temp->next = NULL;
//头指针指向头结点
p = temp;
//3、每创建一个结点,都令其直接前驱结点的指针指向它
for (i = 1; i < 5; i++) {
//创建一个结点
Link* a = (Link*)malloc(sizeof(Link));
a->elem = i;
a->next = NULL;
//每次 temp 指向的结点就是 a 的直接前驱结点
temp->next = a;
//temp指向下一个结点(也就是a),为下次添加结点做准备
temp = temp->next;
}
return p;
}
单链表的使用 #
对于创建好的链表,我们可以依次获取链表中存储的数据,例如:
#include <stdio.h>
#include <stdlib.h>
//链表中节点的结构
typedef struct link {
int elem;
struct link* next;
}Link;
Link* initLink() {
int i;
//1、创建头指针
Link* p = NULL;
//2、创建头结点
Link* temp = (Link*)malloc(sizeof(Link));
temp->elem = 0;
temp->next = NULL;
//头指针指向头结点
p = temp;
//3、每创建一个结点,都令其直接前驱结点的指针指向它
for (i = 1; i < 5; i++) {
//创建一个结点
Link* a = (Link*)malloc(sizeof(Link));
a->elem = i;
a->next = NULL;
//每次 temp 指向的结点就是 a 的直接前驱结点
temp->next = a;
//temp指向下一个结点(也就是a),为下次添加结点做准备
temp = temp->next;
}
return p;
}
void display(Link* p) {
Link* temp = p;//temp指针用来遍历链表
//只要temp指向结点的next值不是NULL,就执行输出语句。
while (temp) {
Link* f = temp;//准备释放链表中的结点
printf("%d ", temp->elem);
temp = temp->next;
free(f);
}
printf("\n");
}
int main() {
Link* p = NULL;
printf("初始化链表为:\n");
//创建链表{1,2,3,4}
p = initLink();
//输出链表中的数据
display(p);
return 0;
}
程序中创建的是带头结点的链表,头结点的数据域存储的是元素 0,因此最终的输出结果为:
0 1 2 3 4
如果不想输出头结点的值,可以将 p->next 作为实参传递给 display() 函数。
如果程序中创建的是不带头结点的链表,最终的输出结果应该是:
1 2 3 4
5. 双向链表 #

目前我们所学到的链表,无论是动态链表还是静态链表,表中各个节点都只包含一个指针(游标),且都统一指向直接后继节点,这类链表又统称为单向链表或单链表。
虽然单链表能 100% 存储逻辑关系为 “一对一” 的数据,但在解决某些实际问题时,单链表的执行效率并不高。例如,若实际问题中需要频繁地查找某个结点的前驱结点,使用单链表存储数据显然没有优势,因为单链表的强项是从前往后查找目标元素,不擅长从后往前查找元素。
解决此类问题,可以建立双向链表(简称双链表)。
从名字上理解双向链表,即链表是 “双向” 的,如下图所示:
“双向”指的是各节点之间的逻辑关系是双向的,头指针通常只设置一个。
从上图中可以看到,双向链表中各节点包含以下 3 部分信息(如下图所示):
- 指针域:用于指向当前节点的直接前驱节点;
- 数据域:用于存储数据元素。
- 指针域:用于指向当前节点的直接后继节点;

因此,双链表的节点结构用 C 语言实现为:
typedef struct line{
struct line * prior; //指向直接前趋
int data;
struct line * next; //指向直接后继
}Line;
双向链表的创建 #
同单链表相比,双链表仅是各节点多了一个用于指向直接前驱的指针域。因此,我们可以在单链表的基础轻松实现对双链表的创建。
需要注意的是,与单链表不同,双链表创建过程中,每创建一个新节点都要与其前驱节点建立两次联系,分别是:
- 将新节点的 prior 指针指向直接前驱节点;
- 将直接前驱节点的 next 指针指向新节点;
这里给出创建双向链表的 C 语言实现代码:
Line* initLine(Line* head) {
Line* list = NULL;
head = (Line*)malloc(sizeof(Line));//创建链表第一个结点(首元结点)
head->prior = NULL;
head->next = NULL;
head->data = 1;
list = head;
for (int i = 2; i <= 5; i++) {
//创建并初始化一个新结点
Line* body = (Line*)malloc(sizeof(Line));
body->prior = NULL;
body->next = NULL;
body->data = i;
//直接前趋结点的next指针指向新结点
list->next = body;
//新结点指向直接前趋结点
body->prior = list;
list = list->next;
}
return head;
}
双向链表的使用 #
我们可以尝试着在 main 函数中输出创建的双链表,C 语言代码如下:
#include <stdio.h>
#include <stdlib.h>
typedef struct line {
struct line* prior; //指向直接前趋
int data;
struct line* next; //指向直接后继
}Line;
Line* initLine(Line* head) {
int i;
Line* list = NULL;
head = (Line*)malloc(sizeof(Line));//创建链表第一个结点(首元结点)
head->prior = NULL;
head->next = NULL;
head->data = 1;
list = head;
for (i = 2; i <= 5; i++) {
//创建并初始化一个新结点
Line* body = (Line*)malloc(sizeof(Line));
body->prior = NULL;
body->next = NULL;
body->data = i;
//直接前趋结点的next指针指向新结点
list->next = body;
//新结点指向直接前趋结点
body->prior = list;
list = list->next;
}
return head;
}
//输出链表中的数据
void display(Line* head) {
Line* temp = head;
while (temp) {
//如果该节点无后继节点,说明此节点是链表的最后一个节点
if (temp->next == NULL) {
printf("%d\n", temp->data);
}
else {
printf("%d <-> ", temp->data);
}
temp = temp->next;
}
}
//释放链表中结点占用的空间
void free_line(Line* head) {
Line* temp = head;
while (temp) {
head = head->next;
free(temp);
temp = head;
}
}
int main()
{
//创建一个头指针
Line* head = NULL;
//调用链表创建函数
head = initLine(head);
//输出创建好的链表
display(head);
//显示双链表的优点
printf("链表中第 4 个节点的直接前驱是:%d", head->next->next->next->prior->data);
free_line(head);
return 0;
}
程序运行结果:
1 <-> 2 <-> 3 <-> 4 <-> 5
链表中第 4 个节点的直接前驱是:3



