1. 树概述 #
树的定义 #
前面章节给大家介绍的都是线性存储结构,包括顺序表、链表、栈、队列、数组。从本节开始,带大家学习一种非线性存储结构,称为树存储结构。
树结构通常用来存储逻辑关系为 “一对多” 的数据。例如:
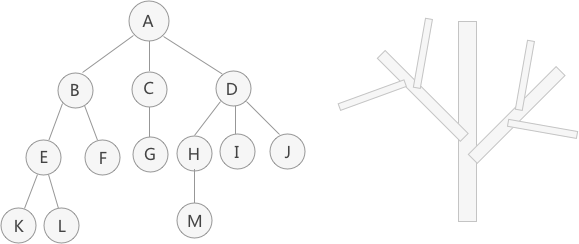
上图的这些元素具有的就是 “一对多” 的逻辑关系,例如元素 A 同时和 B、C、D 有关系,元素 D 同时和 A、H、I、J 有关系等。 观察这些元素之间的逻辑关系会发现,它们整体上很像一棵倒着的树上右图倒过来),这也是将存储它们的结构起名为“树”(或者 “树形”)的原因。
存储具有 “一对多” 逻辑关系的数据,数据结构推荐使用树存储结构。
概念与术语 #
就好像学习链表要知道 “结点” 代表什么意思。系统学习树存储结构之前,也必须了解一些相关的术语。
1) 结点
和链表类似,树存储结构中也将存储的各个元素称为 “结点”。例如在上图中,元素 A 就是一个结点。
对于树中某些特殊位置的结点,还可以进行更细致的划分,比如:
- 父结点(双亲结点)、孩子结点和兄弟结点:以上图中的结点 A、B、C、D 为例,A 是 B、C、D 结点的父结点(也称为“双亲结点”),而 B、C、D 都是 A 结点的孩子结点(也称“子结点”)。对于 B、C、D 来说,它们都有相同的父结点,所以它们互为兄弟结点;
- 树根结点(简称 “根结点” ):特指树中没有双亲(父亲)的结点,一棵树有且仅有一个根结点。例如上图中,结点 A 就是整棵树的根结点;
- 叶子结点(简称 “叶结点” ):特指树中没有孩子的结点,一棵树可以有多个叶子结点。例如上图中,结点 K、L、F、G、M、I、J 都是叶子结点。
2) 子树
仍以上图的树为例,A 是整棵树的根结点。但如果单看结点 B、E、F、K、L 组成的部分来说,它们也组成了一棵树,结点 B 是这棵树的根结点。通常,我们将一棵树中几个结点构成的“小树”称为这棵树的“子树”。
知道了子树的概念后,树也可以这样定义:树是由根结点和若干棵子树构成的。例如,上图这棵树就是由结点 A 和分别以 B、C、D 为根节点的子树构成。
注意:单个结点也可以看作是一棵树,该结点即为根结点。例如上图中,结点 K、L、F 各自就可以看作是一棵树,只不过树中只有一个根节点而已。
3) 结点的度
一个结点拥有子树的个数,就称为该结点的度(Degree)。例如上图中,根结点 A 有 3 个子树,它们的根节点分别是 B、C、D,因此结点 A 的度为 3。
比较一棵树中所有结点的度,最大的度即为整棵树的度。比如上图中,所有结点中最大的度为 3,所以整棵树的度就是 3。
4) 结点的层次
从一棵树的树根开始,树根所在层为第一层,根的孩子结点所在的层为第二层,依次类推。
对于上图这棵树来说,A 结点在第一层,B、C、D 为第二层,E、F、G、H、I、J 在第三层,K、L、M 在第四层。
树中结点层次的最大值,称为这棵树的深度或者高度。例如上图这棵树的深度为 4。
如果两个结点的父结点不同,但它们父结点的层次相同,那么这两个结点互为堂兄弟。例如上图中,结点 G 和 E、F、H、I、J 的父结点都在第二层,所以它们互为堂兄弟。
5) 有序树和无序树
如果一棵树中,各个结点左子树和右子树的位置不能交换,那么这棵树就称为有序树。反之,如果树中结点的左、右子树可以互换,那么这棵树就是一棵无序树。
在有序树中,结点最左边的子树称为 “第一个孩子”,最右边的称为 “最后一个孩子”。拿上图这棵树来说,如果它是一棵有序树,那么以结点 B 为根结点的子树为整棵树的第一个孩子,以结点 D 为根结点的子树为整棵树的最后一个孩子。
6) 森林
由 m(m >= 0)个互不相交的树组成的集合就称为森林。比如上图中除去 A 结点,那么分别以 B、C、D 为根结点的三棵子树就可以称为森林。
前面讲到,树可以理解为是由根结点和若干子树构成的,而这若干子树本身就是一个森林,因此树还可以理解为是由根结点和森林组成的。
7) 空树(简单了解即可)
空树指的是没有任何结点的树,连根结点都没有。
树的其他表示方式 #

除了上图这样画一棵树之外,还有其它的方式可以表示一棵树。
上图左侧是以嵌套集合的形式表示的(集合之间绝不能相交,即任意两个圆圈不能有交集)。
上图右侧使用的是凹入表示法,最长条为根结点,相同长度的表示在同一层次。例如 B、C、D 长度相同,都为 A 的子结点,E 和 F 长度相同,为 B 的子结点,K 和 L 长度相同,为 E 的子结点,依此类推。
2. 树的存储结构 #
双亲表示法(父亲表示法) #
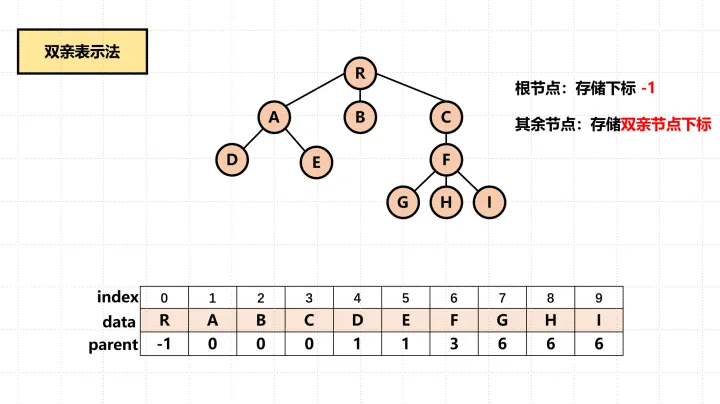
采用的一组连续的存储空间来存储每个节点。根节点没有双亲,所以其在数组中存储的值为-1。其余的节点,只需要存储其父节点对应的数组下标即可。如下图所示:
优缺点:利用了树中除根节点外的每个节点都有唯一的父亲节点这个性质,很容易找到树的根。但无法直接遍历整棵树,需要重构整个树结构。
const int m = 10; //树的节点数
struct node{
int data, parent; //数据域,指针域
};
node tree[m];
孩子表示法 #
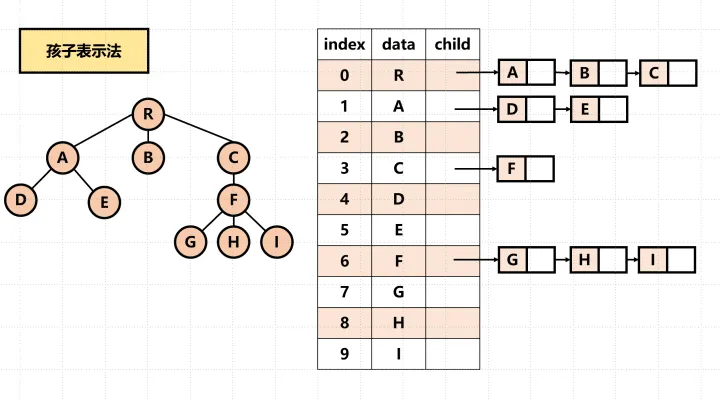
将每个节点的孩子节点都用单链表连接起来形成一个线性结构,n个节点具有n个孩子链表。
还可以这样表示:
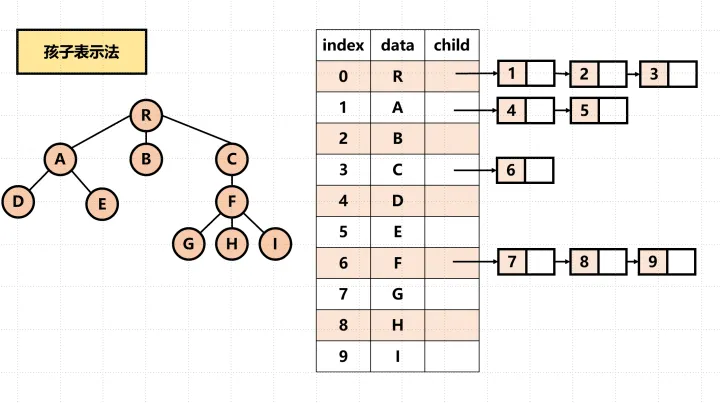
优缺点:只能从根节点遍历到子节点,不能从某个子节点返回到它的父节点。
const int m = 10; //树的度
typedef struct node;
typedef node *tree;
struct node{
char data; //数据域
tree child[m]; //指针域,指向若干孩子节点
};
tree t;
孩子双兄弟表示法 #
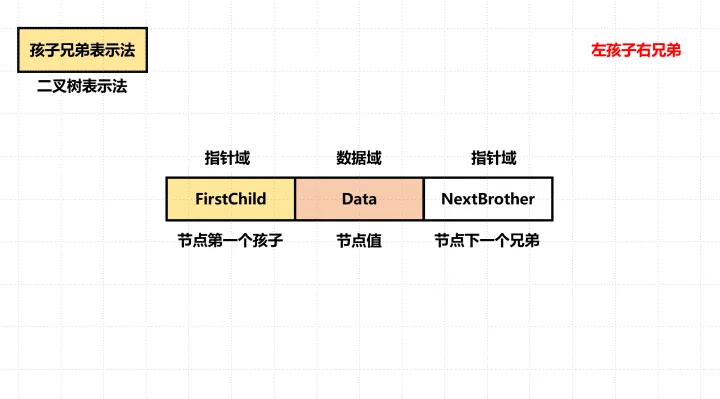
以二叉链表作为树的存储结构,又称二叉树表示法。其中孩子指针域,表示指向当前结点的第一个孩子结点,兄弟结点表示指向当前结点的下一个兄弟结点。
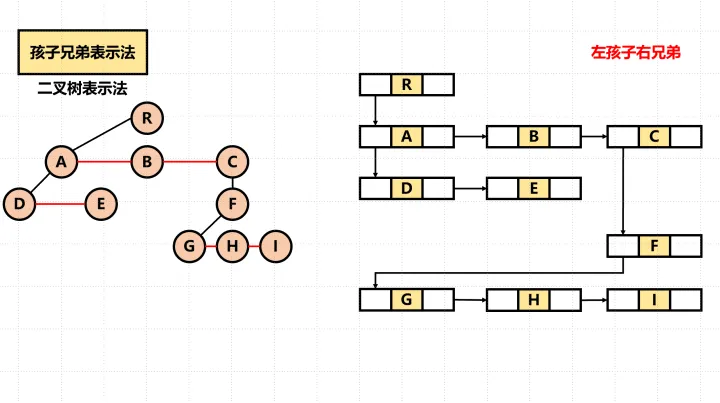
使用孩子兄弟表示法需要将树转换为二叉树。
转化前:
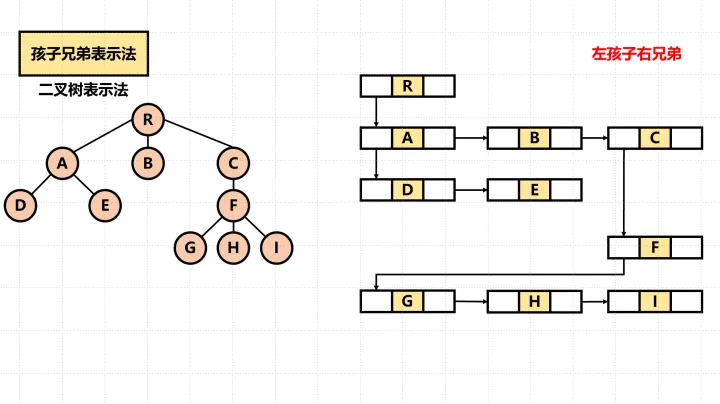
转化后:
typedef struct node;
typedef node *tree;
struct node{
char data; //数据域
tree firstchild, next; //指针域,指向第一个孩子和下一个兄弟节点
};
tree t;
3. 树的遍历 #
遍历的种类 #
树的遍历是一种图的遍历,指的是按照某种规则,不重复地访问某种树的所有节点的过程。具体的访问操作可能是检查节点的值、更新节点的值等。不同的遍历方式,其访问节点的顺序是不一样的。以下虽然描述的是二叉树的遍历算法,但它们也适用于其他树形结构。
树结构有多种不同的遍历方式,从二叉树的根节点出发,节点的遍历分为三个主要步骤:对当前节点进行操作(称为“访问”节点)、遍历左边子节点、遍历右边子节点。这三个步骤的先后顺序也是不同遍历方式的根本区别。
遍历方式的命名,源于其访问节点的顺序。最简单的划分:是深度优先(先访问子节点,再访问父节点,最后是第二个子节点)和广度优先(先访问第一个子节点,再访问第二个子节点,最后访问父节点。 深度优先可进一步按照根节点相对于左右子节点的访问先后来划分。
如果把左节点和右节点的位置固定不动,那么根节点放在左节点的左边,称为前序(pre-order)、根节点放在左节点和右节点的中间,称为中序(in-order)、根节点放在右节点的右边,称为后序(post-order)。对广度优先而言,遍历没有前序中序后序之分:给定一组已排序的子节点,其“广度优先”的遍历只有一种唯一的结果。
前序遍历 #
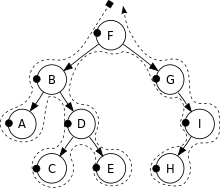
前序遍历(Pre-Order Traversal)是依序以根节点、左节点、右节点为顺序遍历的方式。如下图所示:
深度优先遍历(前序遍历)的结果为:F, B, A, D, C, E, G, I, H。
采用递归方式的算法实现为:
void pre_order_traversal(TreeNode *root) {
// Do Something with root
if (root->lchild != NULL) //若其左子树为空
pre_order_traversal(root->lchild);
if (root->rchild != NULL) //另一侧的子树也做相同事
pre_order_traversal(root->rchild);
}
中序遍历 #
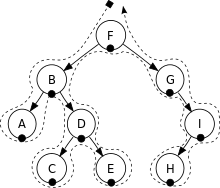
中序遍历(In-Order Traversal)是依序以左节点、根节点、右节点为顺序遍历的方式。
深度优先遍历(中序遍历)的结果为:A, B, C, D, E, F, G, H, I。
采用递归方式的算法实现为:
void in_order_traversal(TreeNode *root) {
if (root->lchild != NULL) //若其中一侧的子树非空则读取取其子树
in_order_traversal(root->lchild);
// Do Something with root
if (root->rchild != NULL) //另一侧的子树也做相同事
in_order_traversal(root->rchild);
}
后序遍历 #
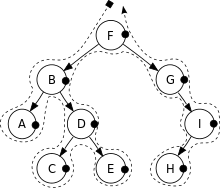
后序遍历(Post-Order Traversal)是依序以左节点、右节点、根节点为顺序遍历的方式。
深度优先搜索(后序遍历)的结果为:A, C, E, D, B, H, I, G, F。
采用递归方式的算法实现为:
void post_order_traversal(TreeNode *root) {
if (root->lchild != NULL) //若其中一侧的子树非空则读取取其子树
post_order_traversal(root->lchild);
if (root->rchild != NULL) //另一侧的子树也做相同事
post_order_traversal(root->rchild);
// Do Something with root
}
层序遍历 #
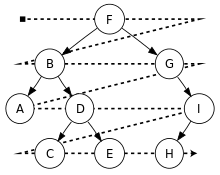
和深度优先遍历不同,广度优先遍历会先访问离根节点最近的节点。二叉树的广度优先遍历又称按层次遍历。
广度优先遍历 – 层次遍历的结果是:F, B, G, A, D, I, C, E, H。
算法借助队列实现:
void level(TreeNode *node)
{
Queue *queue = initQueue();
enQueue(queue, node);
while (!isQueueEmpty(queue))
{
TreeNode *curr = deQueue(queue); //出队操作
// Do Something with curr
if (curr->lchild != NULL)
enQueue(queue, curr->lchild); //左子树入队
if (curr->rchild != NULL)
enQueue(queue, curr->rchild); //右子树入队
}
}



